
JOYSMT
JOY TECHNOLOGY CO.,LIMITED
SMT Equipment | Electronic Component Provider
judy@joysmt.com
+86-13823724660
judy@joysmt.com
+86-13823724660

Location : Home > Service > Technique & Support
Time: 2015-11-19 11:41:37 Source by: www.gladsmt.com
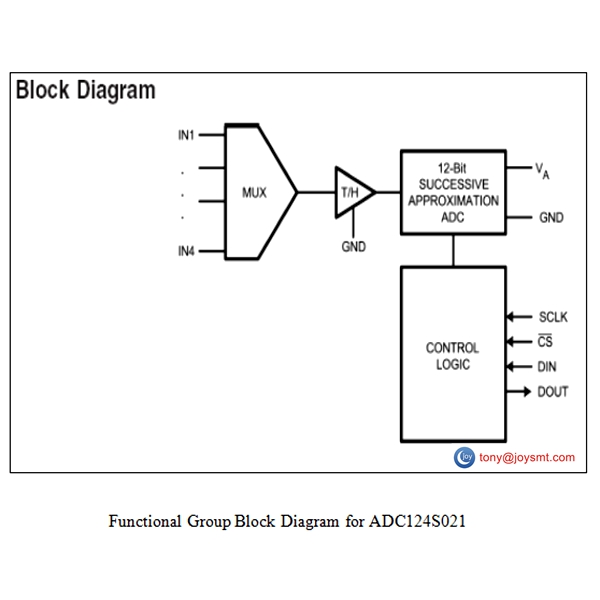
JOY TECHNOLOGY
PRODUCT CATAGORIES











